

Why did humans develop writing and printing?
Why did humans develop writing and printing?
and why Retrieval Augmented Generation strategies are critical for LLMs

There is a big misconception surrounding GPT and other Large Language Models (LLMs): many believe that these models function as massive databases, tapping into the entirety of internet to craft responses to users questions.
It doesn’t work this way.
First, just considering the data size. While GPT's size is impressive, it's estimated to be under 1 million terabytes.
In contrast, the vast expanse of the internet size is more in the billions of terabytes. Comparatively, it's kind of contrasting a water bottle with fifty Olympic-sized swimming pool. The difference is huge.

Going beyond data size, LLMs exhibit an amazing understanding of language, enabling them to abstract and infer based on context. This capability doesn’t come from accessing a vast database of facts but from what we call "parametric knowledge." This enables LLMs to generate the most probable text sequences in response to a given input.
However, it's crucial to distinguish: parametric knowledge isn't synonymous with facts. It is similar to what we use to call “tacit knowledge” in the earlier days of AI.
Think of it this way: an LLM's knowledge reservoir is similar to our human memory. We recall certain facts or phrases from all we've learned, connecting ideas and thoughts seamlessly. Interestingly, common sense facts (like: “fever is bad”) that we experience (and document) over and over is the type of knowledge, intuitive and non implicit, that makes its way into the parameters.
Most of the time, our recollections are accurate, but occasionally, just like anyone, we might mix up details or even embellish a bit. After all, who hasn't done that once in a while? 😉 I certainly have, only to be met with friends or family asking: "Show me the data! You are making up the numbers!".
This is what, in the context of LLMs is called hallucinations and this is this is the #1 reason why, in B2B, LLMs and generative AI haven't (and cannot?) succeeded for tasks heavily dependent on content generation.
Using only parametric knowledge for answering questions is like asking your fresh MBA assistant to help only using its memory , not giving they access to a library or to Google. It is like going back before writing and printing and relying only on “brain to brain” knowledge transfer.
The invention of writing and printing has indeed been a condition for business. Think about it: banking accounts, laws, contracts, records, product descriptions…. there is no business without factual recorded knowledge. Business and B2B demands explicit knowledge.
While it's OK and even desirable to have creative liberties in advertising copy or artistic endeavors (hallucinations are not really a problem for image generation), the stakes are undeniably higher in B2B. B2B applications demand precision, accountability, and trustworthiness and answers must not only be accurate but also verifiable and dependable.
The net is that for B2B, an application cannot depend on parametric knowledge only and has to rely on external sources, using an architecture called Retrieval Augmented Generation.
This architecture works this way:

1- a body of knowledge, specific to the B2B task is built and encoded, sometimes in different formats (semantic vectors, plain text, knowledge graph). (RAG Knowledge set)
2- at inference time, the user query is compared to the RAG knowledge set and the most relevant articles/part of articles are added to the context of the query
3- the augmented prompt is sent to the LLM with instruction to formulate an answer relying on the information present in the context.
A more developed architecture is described in this document from Andreessen Horowitz. It shows (upper right) the need for a Vector database that encodes custom knowledge and is retrieved and passed as context at inference time.
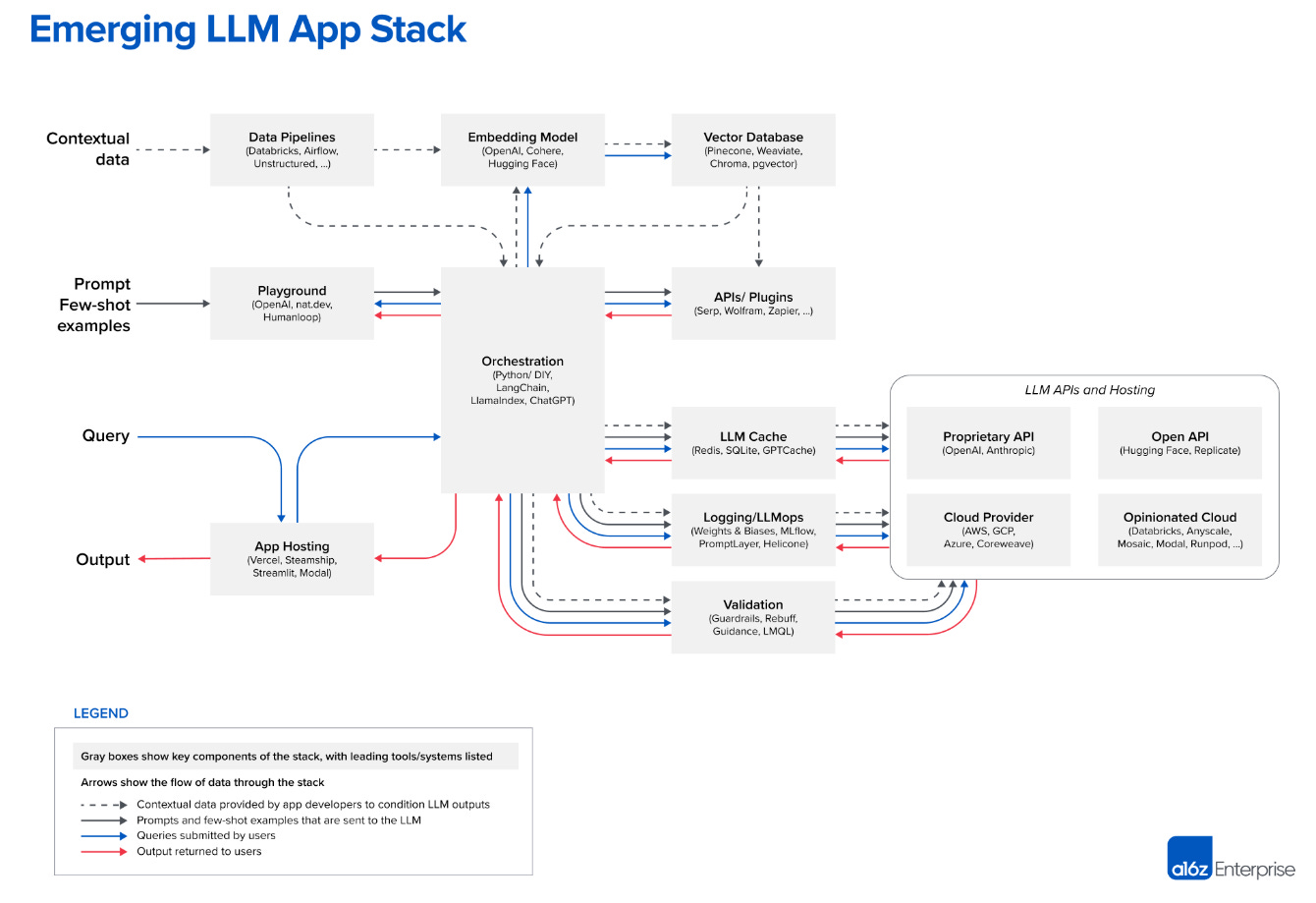
The consequences for Corporations is that B2B generative applications are pivoting towards data and search challenges:
Data Collection Concerns:
Availability and Context: Do we possess the necessary data, and can we pinpoint the relevant context? Should we enrich the data with public, social, private data that are commercially available?
Accuracy and Organization: Is our data precise, and systematically arranged?
Completeness: Are there gaps in our data repository?
Data Structuration Dilemmas:
Storage Modalities: Should our data be housed within a file system, a document management platform, an SQL database, a semantic vector database through embeddings, or perhaps a knowledge graph?
Granularity of Data: What should be the optimal size of our "data chunks"?
Embedding Strategies: Which technique is most suitable for embedding our data?
Search Challenges:
Volume: How many documents should our search retrieve? Keep in mind that although LLMs allow larger and larger contexts, most business models are “pay per token” and the larger the context the more we pay. Plus it is not clear that very large context
Matching: How can we best align the user's "prompt" with our knowledge repository?
Opportunities with NLP:
At every juncture of this process, there are potential enhancements and optimizations that Natural Language Processing (NLP) can offer.
Overall this is not really new. The challenges and approaches resonate with AI & NLP projects that industry professionals have been grappling with since the 1980s.